


Research
Fine-Tuning vs Retrieval Augmented Generation
Which option is better for GenAI applications with your data
July 26 , 2023 by Ofer Mendelevitch & Simon Hughes
Introduction
An increasingly common use-case for Large Language Models (LLMs) is question-answering with your own data. Whether it’s a large set of research papers, or customer service knowledge-base, the ability to just ask a question about this data (which the LLM was not trained on) and get a summarized response is in high demand..
There are two common ways to enable this kind of functionality with LLMs: fine-tuning and Retrieval Augmented Generation. Which one is better?
Fine-tuning a large language model is an important technique that applies transfer learning to adjust an LLM to new data, without training it from scratch.
Contrast that with Vectara’s Grounded Generation (aka Retrieval Augmented Generation), an alternative approach that does not require fine-tuning or any kind of training on your data, and instead utilizes the power of semantic retrieval techniques to provide more context to the LLM at run time.
In this blog post we’ll dive into these two techniques and provide a better understanding of the differences as well as the pros and cons of each approach.
What is Fine-tuning?
Training a deep learning model, and especially large language models, can be quite expensive. For example, researchers estimate the cost to train GPT-3 was around $5m, and the cost to train GPT-4 is estimated at $63m.
The basic cost of training LLMs does decrease over time, thanks to software improvements like Microsoft’s Deepspeed or Stanford’s Flash-Attention as well as GPU hardware improvements like Nvidia’s H100 and others. At the same time, model sizes and sequence lengths continue to increase, and new techniques like MoE drive demand for both memory and compute higher and ultimately higher costs to train these models.
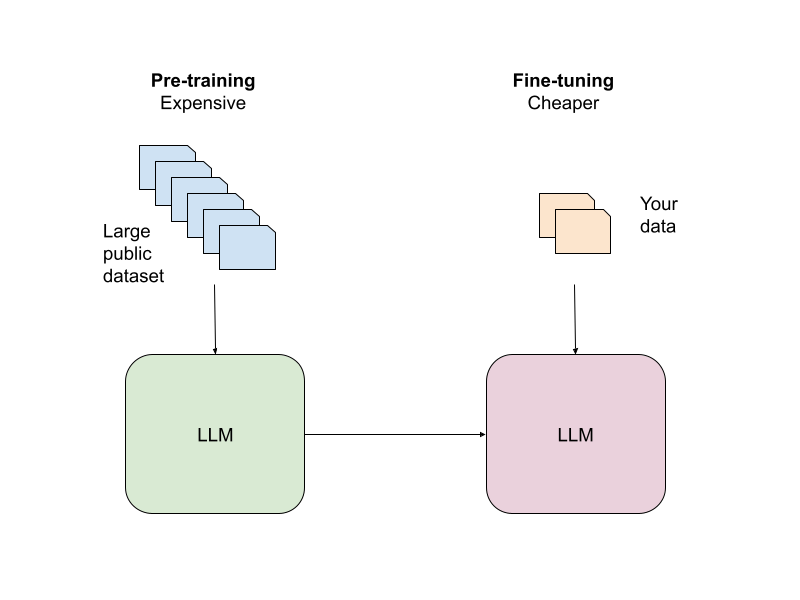
When training an LLM from scratch (also known as pre-training), the weights of the neural network are initialized to random values. As training progresses, they learn from the data and adjust to represent the probability distribution of the text data it’s trained on. Pre-training an LLM imbues the model with an understanding of syntax and grammar rules which are necessary for natural language understanding. It also provides it with a set of common sense knowledge which is needed to make sense of natural language.
The idea of fine-tuning an LLM with new data is to start from a pre-trained model that already has some knowledge of language from its pre-training, and adapt it to a new different dataset. The net effect is that the neural network weights continue to change as the model learns from this new data, which provides the model with specific knowledge taken from this new data. From a computational point of view – because with fine-tuning the model does not start from random weights, the training time is much smaller than pre-training.
What is “Retrieval Augmented Generation”?
Grounded Generation (GG) is Vectara’s approach to Retrieval Augmented Generation, an alternative approach for building LLMs-based GenAI applications with your own data.
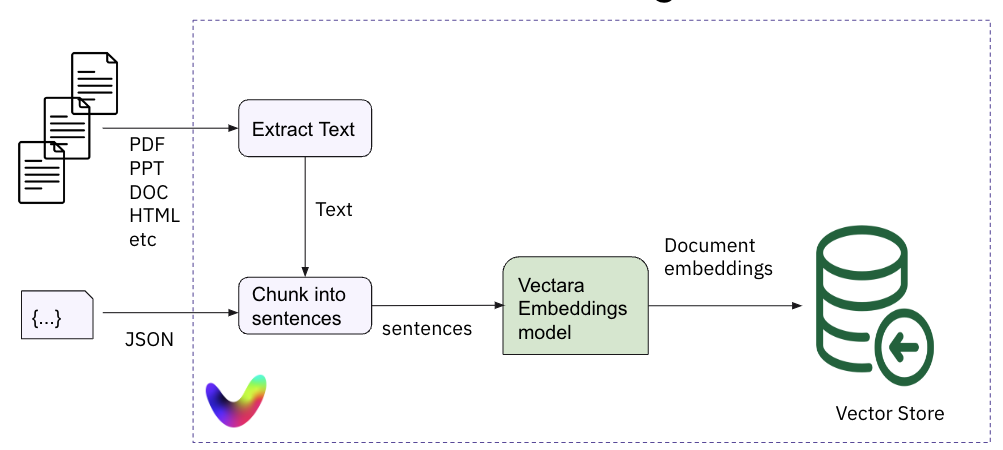
With GG, there are two steps. First, we add text from various document sources (“your data”) into a Vectara corpus. Every document is processed and text is extracted from that document, and split into chunks. Then sentences are encoded into vector embeddings (we use our own embeddings model), and added to an internal vector store:
After documents are encoded as vector embeddings and stored in the vector store, we can now respond to user queries using this text serving as “context” for the LLM.
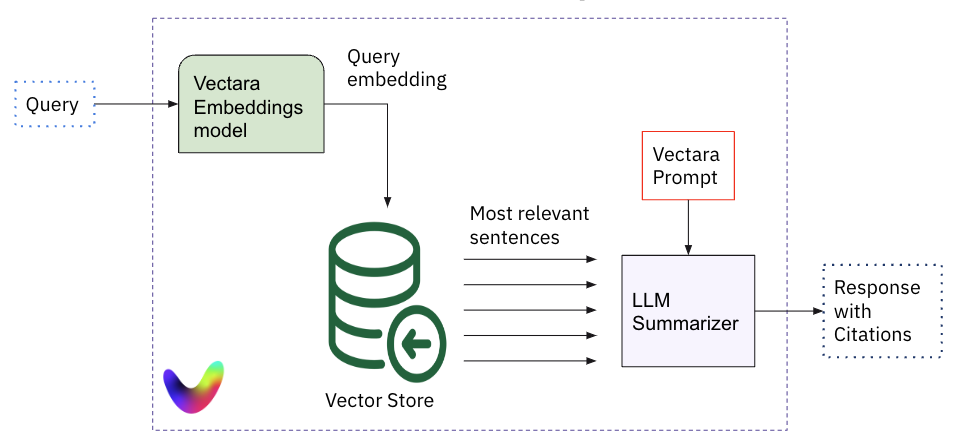
When a user issues a query, the query string is first encoded into an embedding vector, and that vector representation is then used to retrieve the most relevant sentences from the vector store. Then a comprehensive prompt for the summarization LLM is composed from the prompt, along with the relevant facts (or sentences), and sent to the LLM to create the summary or response to the query.
Retrieval Augmented Generation or Fine-tuning: Which should I use?
So, which approach would work better for building GenAI applications grounded on your data?
Let’s explore a few considerations when making that choice.
Can it answer questions from my own data?
At a basic level, both fine-tuning and Retrieval Augmented Generation support the main goal: being able to adapt the LLM to your own data.
The difference is in how they do this.
One can think of the weights of the neural network as capturing some “knowledge graph” that was “learned” during the pre-training process, and is based on the knowledge inherent in that data. With that in mind, by fine-tuning you essentially allow the weights to capture additional knowledge from your own data.
However, the original (very large) dataset used for pre-training is not included in the fine-tuning. Therefore, with fine-tuning there is always a risk of “catastrophic forgetting”, a situation whereby some of the data from the pre-training phase is “forgotten” during fine-tuning. This may negatively impact the overall effectiveness of this approach to both learn about the new data and maintain its original high performance as an LLM, and is especially important to consider if the model is undergoing constant fine-tuning.
It often requires quite a bit of machine learning expertise to ensure no knowledge loss happens, and even for experts in the field – ensuring success is quite tricky.
With Retrieval Augmented Generation, you don’t have any information loss – you simply provide the LLM additional knowledge to be used as context before it responds to the user query.
The tricky part with Grounded Generation is to make sure the facts provided to the LLM are accurate and reflect the best possible information from your own data, which requires a really accurate retrieval engine. If you provide the LLM with bad context or facts, you get a bad response.
Cost of Updates
Fine-tuning is an expensive operation, requiring access to costly GPUs and often the expertise of machine learning engineers to do it right. If your data is relatively stable and does not change often, then fine-tuning is an operation you perform just once or very infrequently (say once a quarter).
If, however, your data changes quite frequently (e.g. once a day or once a week), the cost of fine-tuning can become prohibitively expensive, and it may take too long to update the model in this manner to meet your needs.
In contrast, with Retrieval Augmented Generation, it’s much easier to remain up-to-date with “your data”; when data changes or is updated, you just need to index the new data into the Vectara corpus (an operation that takes seconds), and it’s ready to be used immediately with the next user query.
In this sense, Grounded Generation is superior to fine-tuning and provides a much better cost/value tradeoff.
Data Privacy
If you want to fine-tune on your own data, you can choose to do it yourself, or you can use one of the commercial fine-tuning services like OpenAI or Cohere.
If you fine-tune on your own infrastructure, your data of course, remains private. When considering the use of commercial services for fine-tuning, concerns of privacy often arise – would my data remain private if I send it over to OpenAI or Cohere when I fine-tune?
With Retrieval Augmented Generation, there is no privacy concern, as your data is never integrated into the LLM itself. Instead, the data is used as contextual facts provided to the LLM when responding to a user query. So privacy is maintained – no model is ever trained on your data.
Citing Sources
One of the benefits of Retrieval Augmented Generation is that the LLM returns not only a response to the query, but can also cite the source(s) used to derive its response.
This is not possible with fine-tuning, and only possible with Retrieval Augmented Generation, as the documents used to source the information are returned with the relevant response from the model.
Access Controls
When fine-tuning new data into a model, all the data gets integrated into the pre-trained model to produce the new fine-tuned model. It is thus not possible to have granular controls of access to this information.
For example, if you fine-tune data on your files in Google Drive and would like to control access so that some users may not be able to ask questions about certain sub-folders in Google Drive, while others can – there is no really good way to do that. You either include those files in the fine-tuning, or you do not.
With Retrieval Augmented Generation, granular data controls are possible since the retrieval of text and facts occurs during the query response generation, and the retrieval engine can be directed to prevent some segments of text from being returned if it is not permitted.
The Bottom Line
Should you fine-tune a pre-trained model with your data or use Vectara’s Retrieval Augmented Generation?
If you want to build a specialized LLM based on your own data, and your data is pretty stable and does not change much over long periods of time, then fine-tuning can be a good approach, although you would need to make sure it’s done right and carefully evaluate the performance of the resulting LLM.
For most use cases, however, Grounded Generation provides a superior solution: it can be updated easily in near real-time, costs a lot less, and allows you to maintain full control of your data without the risk of a leak due to the integration of your data into the LLM.
Try Vectara’s Retrieval Augmented Generation today. To get started, sign up for your free account.




