


Data ingestion
Using metadata to enhance your search experience
This blog post describes different patterns for using metadata fields within Vectara, gives a real world example, and provides several code samples so you can learn how to improve the discovery of your data and apply Vectara in a variety of use cases beyond the search box.
November 17 , 2022 by Justin Hayes
The use of large language models in search is revolutionizing how people find information. Spend 5 minutes with an LLM-powered search platform like Vectara and you’ll get amazing search relevance – with no prior language configuration required.

That said, you can further improve your search capability by effectively using metadata fields. Doing so lets your users more quickly hone in on what they want, ensures that the best matches show up earlier in the result list, and enables you to show the results in the most engaging way.
Patterns for Using Metadata
Metadata is information that describes, or gives context to, other data. In the case of files on your computer – the file’s contents are the data, and the file name, size, permissions, create date, etc are the metadata. This approach of using metadata to provide context can be applied to any other type of data.
There are several techniques for using metadata to enhance your search. Each accomplishes a different goal, but they are all built upon the concept of attaching useful bits of information to every piece of indexed content. You can later use that information to adjust how the search is executed or to apply post-processing logic on the results to meet your requirements. The main patterns are listed below:
Query Filtering
You can configure your searches to ignore specific results that don’t meet the criteria, specified as metadata field values. That way, you are able to narrow down the search results to find precisely what the user is looking for. You might want to filter based on a geographic area, or timestamp, or language.
One very useful example of filtering is Attribute Based Access Control. In this technique you “tag” indexed data with metadata fields describing the data and later use those to control which results can be shown to each individual user. For example, you could use a “PII” metadata field that is set if the indexed data contains personally identifiable information. Then when users run searches, you can add a filter clause that blocks any results having the PII field if the user is not permitted to see this type of sensitive data.
Boosting and Burying
It is often useful to modify the search results based on specific attributes of each piece of indexed data. This is called “boosting and burying”, where you increase or decrease a given result’s confidence score based on the metadata associated with the text for that specific result. For example, if you are indexing user comments, you might adjust the scores of each result based on the average number of upvotes it got (see below for more on this example).
Results Enrichment
You may want to show additional information with the search results to make it easier for the user to understand each result or know what to do next. One approach to do this is to look up the additional information for every single search result, but that is very slow. A better approach is to “pass through” the required information by adding it as metadata fields at index-time. Then when processing the results the information is already there for you to use.
For example, when you index each document you could add a metadata field that is a comma-separated list of IDs of related documents. Then when a user does a search and for each result, you can use that field to generate a set of links to the related documents so the user can easily see what to look at next.
Advanced Search Algorithms
In some scenarios you can get significantly better results by running multiple searches in parallel and then “fusing” the results into a single result list. For example, when searching with a given query, you might first run a search with certain filters or boosting rules, then run a second search with different filters/rules, then use Reciprocal Rank Fusion to merge the results. This type of technique is only possible when leveraging metadata associated with your indexed content.

Digital Media Example
For the remainder of the post we will make these concepts tangible with a real world example. Imagine a digital media company whose users discuss consumer products. This discussion takes the form of Posts and threaded Comments, each of which can be given upvotes to indicate quality of the content.
The easier it is for users to find what they need across this vast set of user generated content, the longer they will remain engaged. So we want to use Vectara, and several of the metadata patterns explained above, to accomplish this.
We will rely on the following metadata fields:
- region – which geographic area the user was in when they submitted the content. This will be used for Query Filtering.
- upvotes – the number of upvotes that users have given each Post and Comment, indicating the usefulness of that content. This will be used for results Boosting.
- post_id – the original Post that the content belongs to; if the indexed content is Post itself, this is just that Post’s ID; if the indexed content is a Comment, then this is the ID of the Post to which the Comment belongs. This will be used for Results Enrichment.
Using Metadata in Vectara
There are three categories of metadata fields within Vectara. All are based on the concept, mentioned above, of attaching information to each piece of indexed content. And all are defined within the context of a single Corpus. But how and where they are used differs.
- Automatic Metadata – These are fields that Vectara sets automatically at index time. This includes “lang”, which is added by default as a Filter Attribute when creating a Corpus in the Vectara console, and which can be specified manually if creating a Corpus via API (see below). It is the ISO 639-3 language of the text which can be used for query filtering. This category also includes the “section” and “offset” fields, which do not need to be explicitly defined by the user, as they are exposed automatically in the query results API. These fields explain where to locate the matching result snippet within the entire indexed document.
- Custom Metadata – Additional fields you define at Corpus creation time to be used for query filtering, and for boosting and burying (which is accomplished in Vectara via custom dimensions).
- Pass Through Metadata – Additional fields you attach to data at indexing time, to be used in your search result post-processing code for results enrichment.
This post shows how to create and use metadata filters at Corpus creation time, indexing time, and querying time. In each of these lifecycle stages, there is one code snippet that uses the Vectara REST services (with cURL) and one snippet that uses the gRPC services (with Python). We also give an example showing how to use the Vectara console to create the Corpus.
Corpus Creation
How to specify additional metadata fields to be used for filtering and boosting (custom dimensions) when creating a corpus.
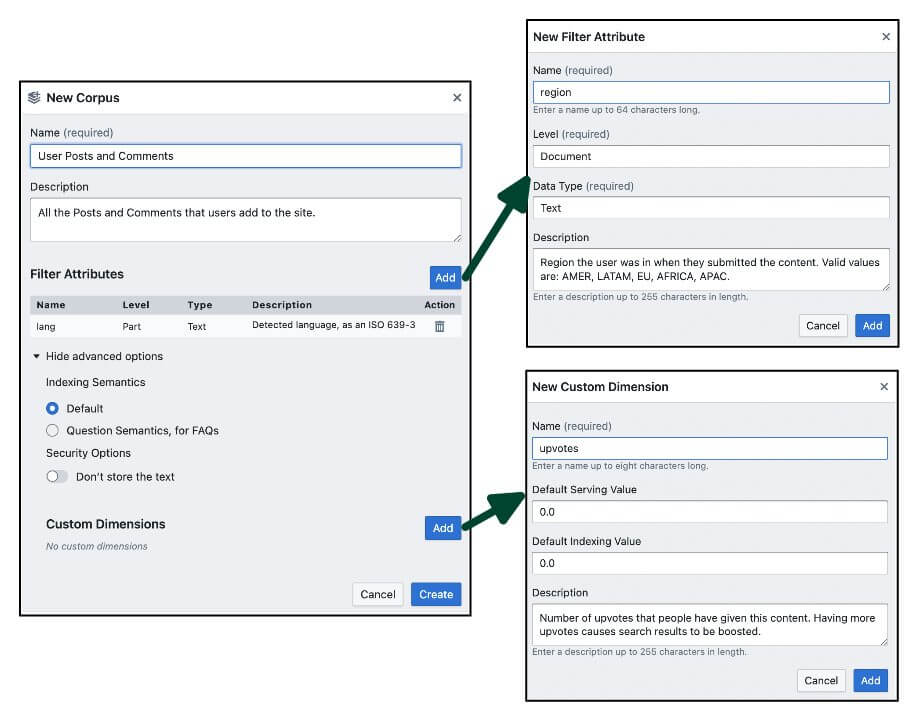
Via the management console:
After clicking on “Create Corpus”, click the “Add” buttons to enter the new metadata fields.
Via REST (using cURL):
curl -X POST \
-H "Authorization: Bearer ${JWT_TOKEN}" \
-H "customer-id: ${CUSTOMER_ID}" \
https://h.admin.vectara.io:443/v1/create-corpus \
-d @- <<END;
{
"corpus":
{
"name": "User Posts and Comments",
"description": "All the Posts and Comments that users add to the site.",
"custom_dimensions": [
{
"name": "upvotes",
"description": "Number of upvotes that people have given this content. Having more upvotes causes search results to be boosted.",
"serving_default": 0,
"indexing_default": 0
}
],
"filter_attributes": [
{
"name": "region",
"description": "Region the user was in when they submitted the content. Valid values are: AMER, LATAM, EU, AFRICA, APAC.",
"indexed": false,
"type": "FILTER_ATTRIBUTE_TYPE__TEXT",
"level": "FILTER_ATTRIBUTE_LEVEL__DOCUMENT"
}
]
}
}
END
Via gRPC (using Python):
# Create corpus object to specify what to create corpus = admin_pb2.Corpus() corpus.name = "User Posts and Comments" corpus.description = "All the Posts and Comments that users add to the site." # Specify custom dimensions custom_dimension = admin_pb2.Dimension() custom_dimension.name = "upvotes" custom_dimension.description = "Number of upvotes that people have given this content. Having more upvotes causes search results to be boosted." custom_dimension.serving_default = 0 custom_dimension.indexing_default = 0 corpus.custom_dimensions.extend([custom_dimension]) # Specify filter attributes filter_attribute = admin_pb2.FilterAttribute() filter_attribute.name = "region" filter_attribute.description = "Region the user was in when they submitted the content. Valid values are: AMER, LATAM, EU, AFRICA, APAC." filter_attribute.indexed = False filter_attribute.type = admin_pb2.FILTER_ATTRIBUTE_TYPE__TEXT filter_attribute.level = admin_pb2.FILTER_ATTRIBUTE_LEVEL__DOCUMENT corpus.filter_attributes.extend([filter_attribute]) filter_attribute = admin_pb2.FilterAttribute() filter_attribute.name = "lang" filter_attribute.description = "Detected language, as an ISO 639-3 code." filter_attribute.indexed = False filter_attribute.type = admin_pb2.FILTER_ATTRIBUTE_TYPE__TEXT filter_attribute.level = admin_pb2.FILTER_ATTRIBUTE_LEVEL__DOCUMENT_PART corpus.filter_attributes.extend([filter_attribute]) # Later on, make the CreateCorpus call using the # admin_pb2 and services_pb2_grpc libraries ...
Indexing
How to add new content into the Corpus, setting metadata fields that can be used for filtering, boosting and burying, and results enrichment.
Via REST (using cURL):
curl -X POST \
-H "Authorization: Bearer ${JWT_TOKEN}" \
https://h.indexing.vectara.io:443/upload?c=${CUSTOMER_ID}&o=${CORPUS_ID} \
-d @- <<END;
{
"documentId": "237a8b63-2826-4ee1-8d83-14c2451a3357",
"parts": [
{
"text": "This peloton bike is constantly breaking.",
"custom_dims": [{
"name": "upvotes",
"value": 14
}],
"metadata_json": "{\"region\":\"AMER\", \"post_id\":13572468}"
}
]
}
END
Via gRPC (using Python):
# Create document to be indexed document = indexing_pb2.Document() document.document_id = "UNIQUE_DOC_ID" document.title = "TITLE OF USER GENERATED CONTENT" # Add the metadata fields to the document metadata = dict() metadata["upvotes"] = 14 metadata["region"] = "AMER" metadata["post_id"] = 13572468 document.metadata_json = json.dumps(metadata) # Create one section for the actual content section = indexing_pb2.Section() section.text = "BODY OF USER GENERATED CONTENT" document.section.extend([section]) # Later on, make the Index call using the # services_pb2 and services_pb2_grpc libraries ...
Querying
How to use query filtering and boosting (custom dimensions) when running a query. Additionally, how to extract metadata fields when processing search results to enrich what is shown to the user.
Note: only the metadata fields that you explicitly specify as filterable at corpus creation time can be added to the filter expression. Other fields that are added automatically (such as “Content-Encoding”) or that you provide as “pass through” fields are not filterable. Additionally, field names used in filtering are case sensitive.
Filtering Query String Example – specified in addition to a normal query string when running a search:
doc.region='AMER' and part.lang='eng'
Via REST (using cURL):
request = serving_pb2.BatchQueryRequest()
query = request.query.add()
query.query = "How durable are peloton bikes?"
query.num_results = 5
corpus_key = query.corpus_key.add()
corpus_key.customer_id = 189
corpus_key.corpus_id = 264
dim = corpus_key.dim.add()
dim.name = "upvotes"
dim.weight = 0.01
corpus_key.metadata_filter = "doc.region='AMER' and part.lang='eng'"
...
response = query_stub.Query(request, ...)
...
# Use the "post_id" metadata field to output a
# link to view the full Post submitted by the user
for response in response_set.response:
# Get the "post_id" field
post_id_field = [metadata for metadata in response.metadata if metadata.name == "lang"]
if post_id_field:
# Call the function to output the Post link
print_post_link(post_id_field[0].value)
Next Steps
To learn more about how to use metadata with Vectara, visit our Custom Dimensions and Filtering documentation. Also, there are several Getting Started examples that provide complete applications which you can start with to further explore Vectara or to build out your own application.
Good luck, and happy building!





